在上一篇文章使用Prometheus Pusher实现跨环境监控中笔者分享了Prometheus的一些基本概念,包括架构,数据模型,查询API以及表达式等内容。
在这边文章中笔者将会详细介绍在kubernetes平台下部署Prometheus,以及监控kubernetes平台中部署的应用的信息。
总体目标
从监控平台本身的业务需求分析来看,我们至少应该希望通过Prometheus平台获取到一下监控数据:
性能指标
- 容器相关的性能指标数据(如:cpu, memory, filesystem;
- Pod相关的性能指标数据;
- 主机节点相关的性能指标数据;
服务健康状态监控
- Deployment相关的健康状态(health or unhealth);
- Pod的健康状态;
- 主机Node节点的健康状态
除了获取监控数据意外,我们还需要对一些特定的异常情况进行告警,因此需要配合使用AlertManager使用告警通知
实现思路和要点
1,容器和Pod相关的性能指标数据
kubernetes在部署完成后会在每个主机节点上内置cAdvisor,因此可以直接用过cAdvisor提供的metrics接口获取到所有容器相关的性能指标数据。
2,主机性能指标数据
Prometheus社区提供的NodeExporter项目可以对于主机的关键度量指标状态监控,通过kubernetes的Deamon Set我们可以确保在各个主机节点上部署单独的NodeExporter实例,从而实现对主机数据的监控
3,资源对象(Deployment, Pod以及Node)的健康状态
坏消息是Prometheus社区并没有直接提供对于kubernetes资源的健康状态采集的Exporter,好消息是Prometheus的架构体系我们可以快速扩展我们自己的Exporter从而实现对kubernetes的资源对象健康状态数据的采集,因此这个部分我们需要基于kubernetes API实现自己的kubernetes Exporter
4,Prometheus如何动态发现采集Target的地址
Promentheus最基本的数据采集方式是用过在yml文件中直接定义目标Exporter的的访问地址,此刻Prometheus可以根据Target地址定时轮训获取监控数据。同时Prometheus还支持动态的服务发现注册方式,具体信息可以参考Prometheus官方文档,这里我们主要关注在kubernetes下的采集目标发现的配置,Prometheus支持通过kubernetes的Rest API动态发现采集的目标Target信息,包括kubernetes下的node,service,pod,endpoints等信息。因此基于kubernetes_sd_config以及之前提到的三点,我们基本了解了整个的一个实现实例。
Step By Step
DaemonSet部署NodeExporter服务
1 | # node-exporter-ds.yml |
在Service中定义标注prometheus.io/scrape: ‘true’,表明该Service需要被prometheus发现并采集数据
使用RBC创建Cluster Role并设置访问权限
1 | apiVersion: rbac.authorization.k8s.io/v1beta1 |
通过RBC创建ClusterRole,ServiceAccount以及ClusterRoleBinding从而确保Prometheus可以通过kubernetes API访问到全局资源信息

创建Prometheus配置文件ConfigMap
1 | apiVersion: v1 |
Prometheus可以在容器内通过DNS地址 https://kubernetes.default.svc 访问kubernetes的Rest API.
rule_files则定义了告警规则的文件匹配规则,这里会加载/etc/prometheus-rules/下所有匹配*.rules的文件
创建AlertManager配置文件ConfigMap
1 | kind: ConfigMap |
在Alertmanager的配置文件中我们定义了两种基本的通知方式,邮件以及Slack对于产生的告警默认情况下都会通知到slack的特定channel,这里prometheus主要集成了Slack的incoming-webhooks,从而实现基于slack的告警通知,对于某些告警当存在label为severity:email则通过还会通过邮件发送告警信息。
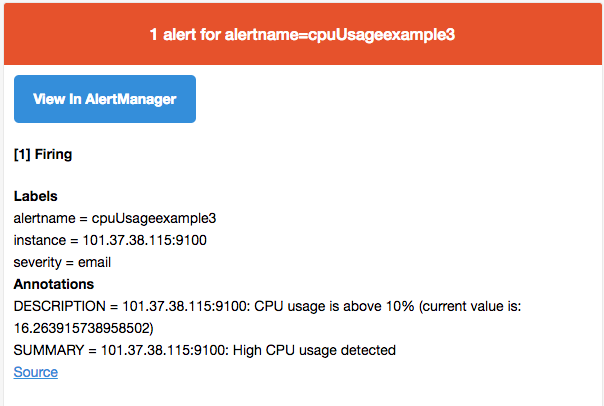
例如如果在prometheus中定义了告警规则
1 | ALERT NodeCPUUsage |
则当主机的CPU使用率草果75%后会触发告警,由于告警包含标签severity=”email,因此当alertmanager接收到告警信息会会通过stmp协议发送告警邮件
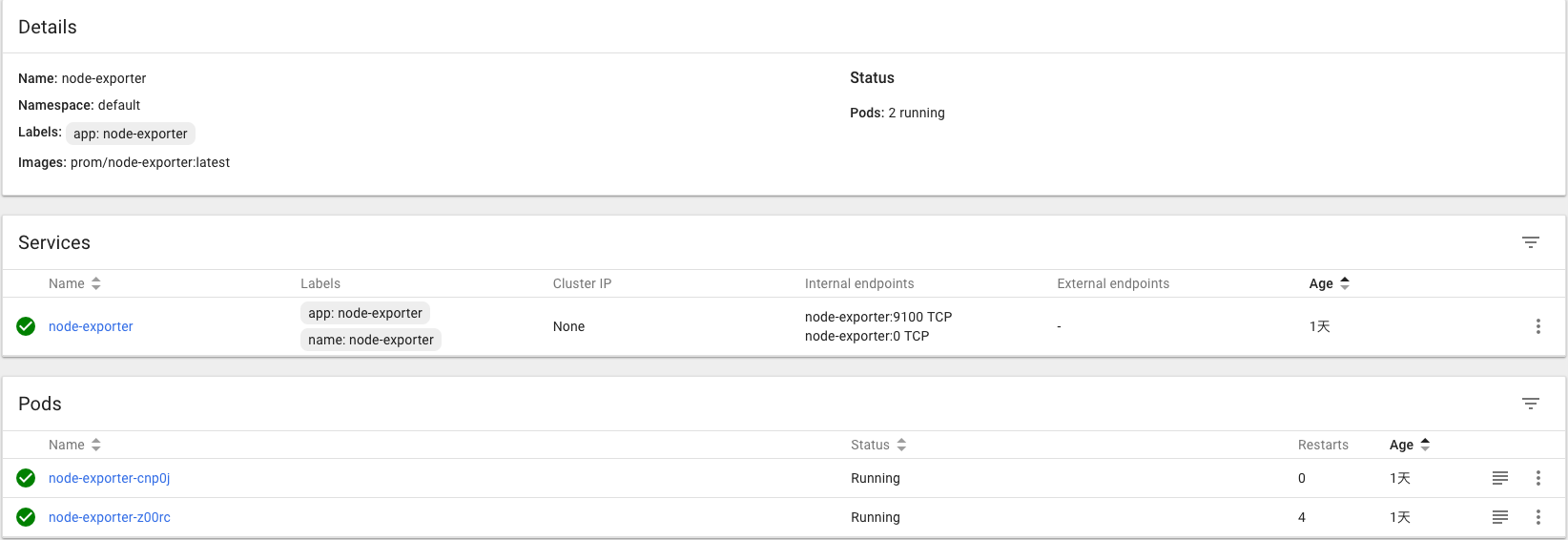
部署自定义kubernetes Exporter获取kubernetes下主要资源对象的健康状态
1 | apiVersion: v1 |
这里不详细展开如果实现自定义实现Prometheus的Exporter,源码可以通过https://github.com/yunlzheng/kubernetes-exporter获取。
这里由于kubernetes Exporter同样需要访问全局kubernetes资源,因此使用了之前步骤定义的ServiceAccount从而可以通过kubernetes API获取到deployments,pod,service等资源的详细信息,从而通过/metrics接口暴露相关信息。这里Service中同样标注了 prometheus.io/scrape: ‘true’从而确保prometheus会采集数据。
部署Prometheus和Alertmanager的Deployment
1 | apiVersion: v1 |
需要注意的是这里我们明确使用了上一步定义的ClusterRole和Service Acoount1
2serviceAccountName: prometheus
serviceAccount: prometheus
因此Prometheus可以在容器内通过DNS地址 https://kubernetes.default.svc 访问kubernetes的Rest API地址.同时访问API所需的认证信息以及https的ca证书信息可以从文件
/var/run/secrets/kubernetes.io/serviceaccount/token和/var/run/secrets/kubernetes.io/serviceaccount/ca.crt读取,从而确保prometheus具有权限并且可以发现采集的目标资源。
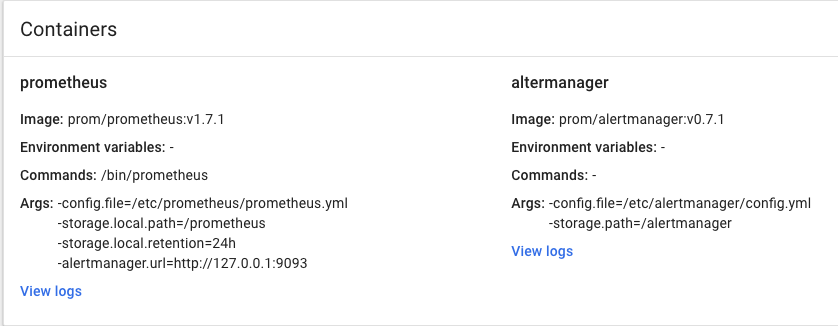
同时由于promentheus和alertmanager部署在同一个pod当中,因此prometheus可以直接通过127.0.0.1:9073推送告警信息到alertmanager
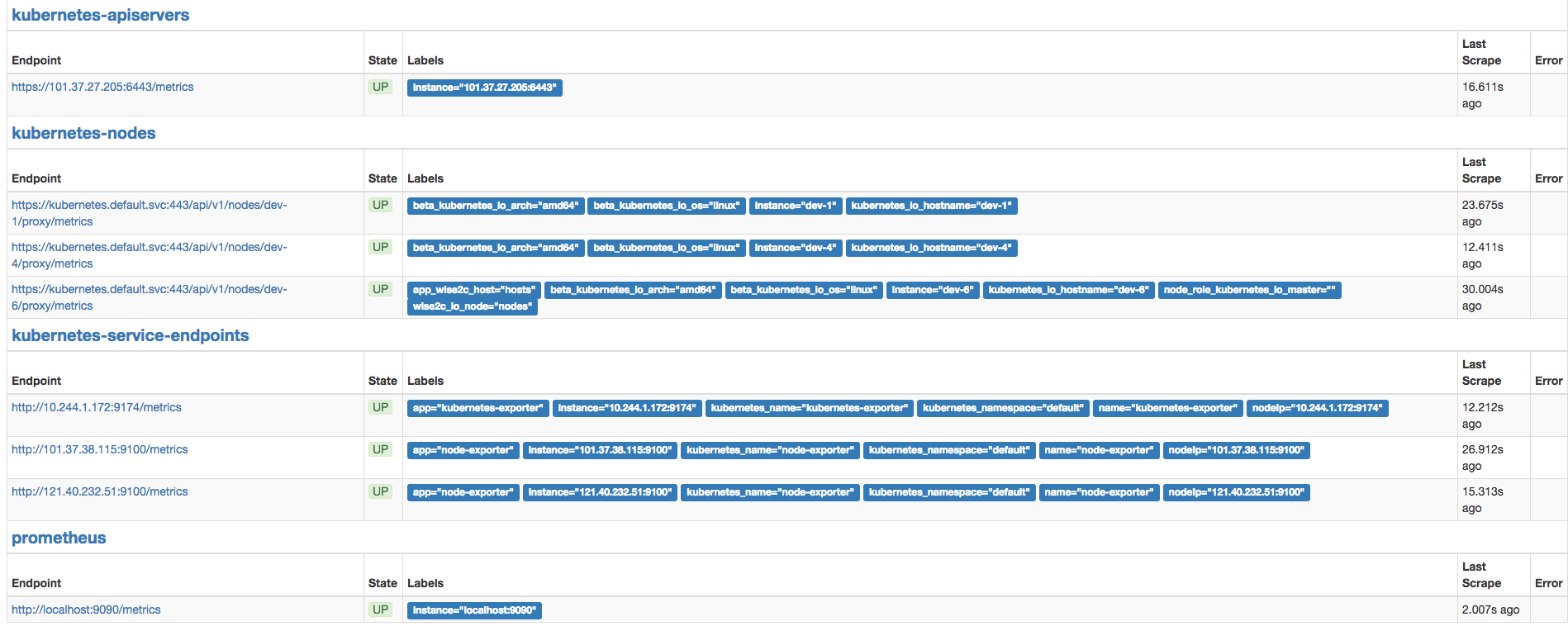
访问prometheus网页我们可以查看当前的所有target信息
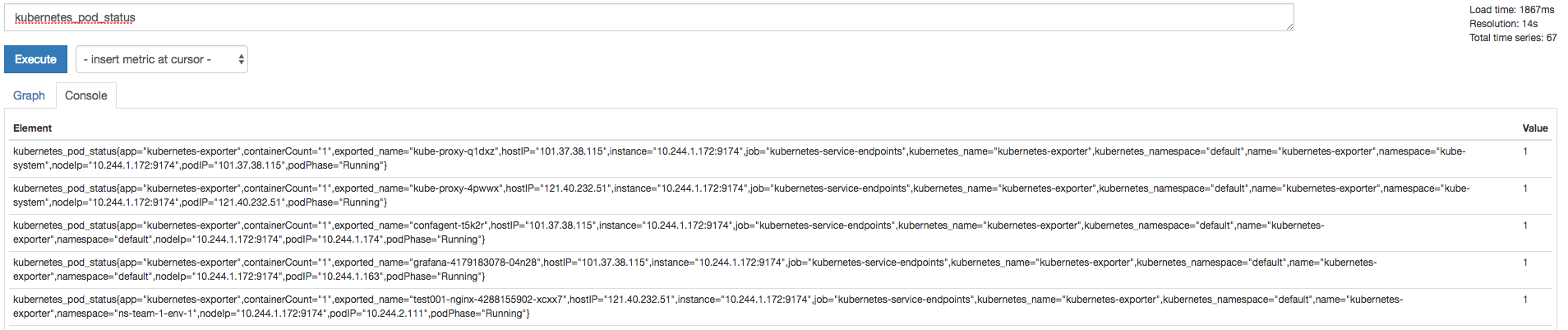
通过表达式查询kubernates的pod健康状态
查看告警信息

总结
在本文中我们以在总体目标为背景定义了在Kubernates下部署promentheus监控平台的总体目标,并且一次目标分析了细线的基本实例,最后给出了在Kubernates部署Promentheus的具体步骤。