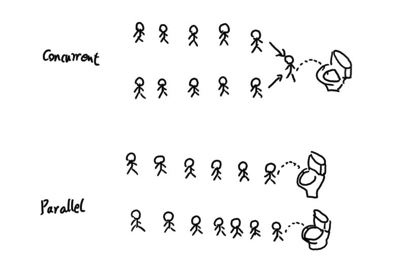
并发与并行
对于操作系统而言,一个单核的CPU就像写字楼中一层只有一个马桶一样。 即使有再多的人想要用,也不可能让两个人同时使用。因此只能将时间片段分配个每一个人单独利用。 当CPU被占用时,其他人只能等待。这种方式就叫做并发(concurrency)。
而多余多核CPU而言,就好多了。可以有不同的人同时使用,这种就叫做并行(Paralle)。 并行强调时间上的同时发生。
而一个程序(即一个进程)运行过程中,不会说这个程序(进程)占用了多少CPU时间,而是说这个进程中派生出的线程(Thread)占用了多少CPU时间。 在操作系统中进程是操作系统资源调度和分配的基本单位,而线程才是CPUdi调度和分配的单位。线程才是上图中的那些小人儿。
Java创建线程有两种方式。一种直接继承Thread类,复写run()方法。在使用时,直接新建一个线程对象,然后使用new MyThread().start()启动线程;
1 | public class MyThread extends Thread { |
另外一种方式是实现Runable接口。使用时使用new Thread(new MyRunable()).start()。
1 | public class MyRunable implements Runnable { |
一般来说我们更推荐使用第二种方式,直接继承Thread,会让实现关注了线程自身的行为。 而实际上我们只需要让这个线程运行点什么东西就行了。下文中的线程池也很好的佐证了这样的思路。
当然从理论上讲线程越多,抢占到CPU使用时间的可能性就越大,越多的CPU使用时间就等于越快的处理速度。(注意适可而止,线程的创建和销毁都会消耗资源,线程太多系统也会崩溃掉的)。
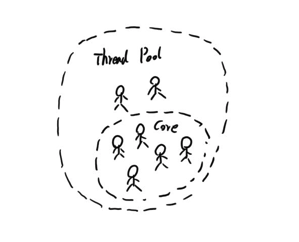
线程池
上一部分说了,虽然理论上讲,线程越多程序可能更快,但是在实际使用中我们需要考虑到线程本身的创建以及销毁的资源消耗,以及保护操作系统本身的目的。我们通常需要将线程限制在一定的范围之类,线程池就起到了这样的作用。
和所有的池一样,都需要喂养一些东西。线程池中喂养的就是我们的线程,通常来说线程池中会有一定数量的核心线程配比,以及一定的Buffer配比。一定的Buffer比例可以让系统适应并发压力的波动,而固定数量的核心线程,可以确保减少线程创建以及销毁的资源损耗。 这样当有任务需要执行的时候,那就直接把任务丢给线程池就好了。
Java提供了以下方式来创建线程池:
1 | ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<>()); |
TheadPoolExecutor的构造函数定义如下:
1 | public ThreadPoolExecutor(int corePoolSize, |
其中corePoolSize用于指定核心线程数量,maximumPoolSize指定最大线程数,keepAliveTime和TimeUnit指定线程空闲后的最大存活时间,workQueue则是线程池的缓冲队列。还未执行的线程会在队列中等待。java中提供的Executors提供了多种默认的线程池实现。
异步与并行
在经常接触Java Web开发的同学都知道应用服务器如(Tomcat),会为每一个请求分配一个独立的线程。因此在大部分情况下,都不需要考虑多线程的问题。
例如,可以通过修改Tomcat的配置,修改其线程池的相关配置。
1 | <Connector port="8080" |
但是对于每一个Request而言,假如对应了多个业务操作,特别是在微服务的方式中可能还会远程调用多个其它远程服务,会使得该Request的响应时间过长,降低系统的吞吐量。
因此为了提升系统的吞吐量(注意,不是并发量,并发量由Webserver的线程池大小决定)。可以使用异步的方式对请求进行处理。将这些远程调用,变成异步的方式,而在外部等待这些异步操作执行完成后,对结果进行汇集后再返回给客户端。 响应时间减少到最长远程调用的时间。

除了以上的方式以外,如果业务操作时间就非常长,可能就需要结合消息队列的方式对请求进行处理。当客户端发起请求后,理解响应Accepted,告诉客户端,“朕知道了,我会慢慢处理,你先下去吧”。然后由后台任务对业务进行处理即可。
使用Future实现并发
在前面的部分,介绍过在Java中使用Thread和Runnable实现多线程程序,这种模式下调用者并不关心线程的返回状态,直接把线程丢给线程池执行即可。而有些情况下,调用者是需要了解线程中任务的执行结果,然后对结果进行汇集。在还没有Future之前,可以使用CountDownLatch的方式。
例如,这里有一个远程调用的服务RemoteService:
1 |
|
为了模拟远程调用的等待时间,这里随机让线程sleep一段时间。
1 | package com.github.concurrent; |
在上述的代码中,为了能够以多线程的方式实现对远程服务的调用,并且需要获取结果时,专门将RemoteService包装到了一个Runnable当中。 那有没有更简单的方式?答案是:Future。
下面的代码演示了如何通过Future简化上述代码:
1 | package com.github.concurrent; |
Future可以在不阻塞主线程的情况下,进行异步调用,并且监视远程调用的返回结果。 当需要得到异步任务的结果时,再通过get方法获取。
未完待续: 使用CompletableFuture对Future进行编排