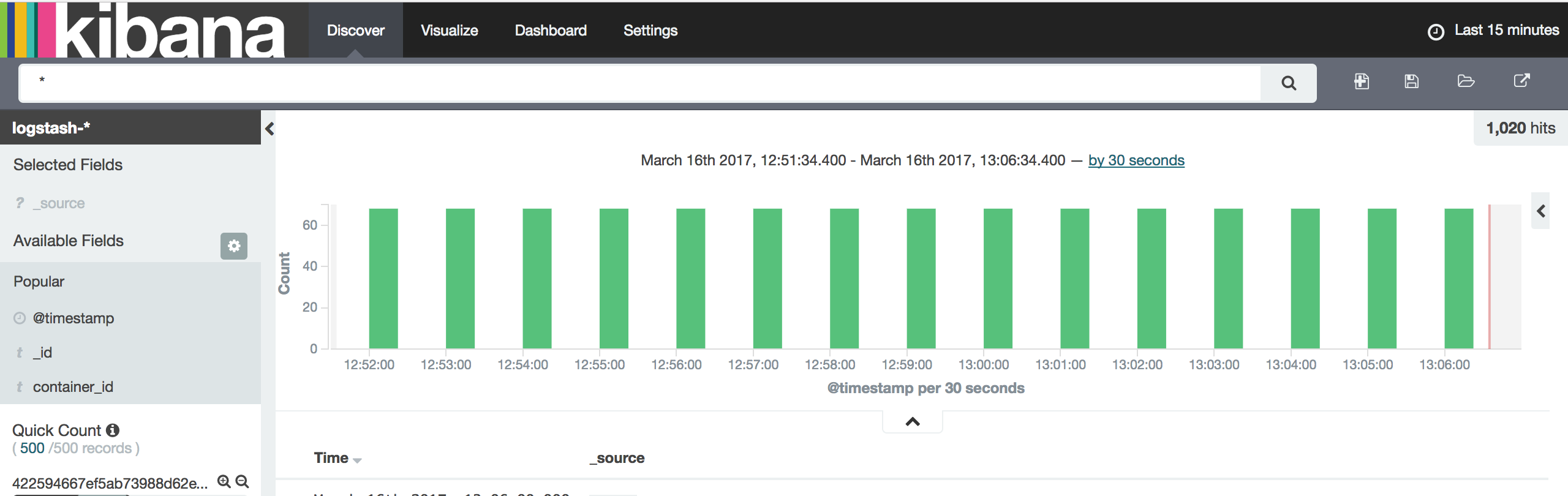
微服务是这样一种软件架构模式:独立进程,独立部署,独立发布。而一个业务通常会由多个服务进行支撑,这就带来一个问题,当用户的操作分布到了不同的服务当中之后,如果出现了异常开发人员如何才能快速完成问题定位?这篇文章我们就来聊聊关于日志的那些事儿
场景假设
假定我们有这样一个项目:
- 前端使用是独立构建的Vuejs应用程序;
- API Gateway代理所有的前端请求同时提供认证授权接口;
- 对于所有后端服务的请求实际都由API Gateway完成;
- 后端有4个不同的服务分别提供不同的功能;
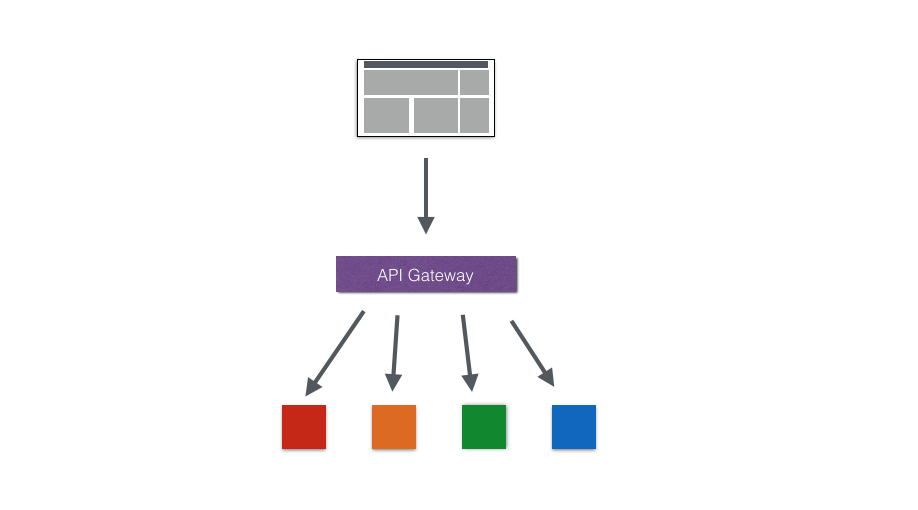
基于微服务架构我们可以实现服务的独立部署,独立发布。而一个业务通常会由多个服务进行支撑,这就带来一个问题,当用户的操作分布到了不同的服务当中之后,如果出现了异常开发人员如何才能快速完成问题定位。
容器日志聚合
对于Docker容器而言,通常有两种方式来进行日志的聚合分析。
- docker logging driver
docker原生支持多种logging driver用于支持用户从容器中获取输出信息
| 驱动 | 描述 |
|---|---|
| none | 容器不会产生任何日志输出,docker logs不会显示任何信息 |
| json-file | 默认设置,将日志格式化为json并且保存到文件 |
| syslog | docker将会日志输出到syslog,需要在主机上运行syslog进程 |
| fluentd | 将日志输出到fluentd,fluentd需要提供forward源支持, docker logs无法查看日志信息 |
| 其它 | 点击查看详情 |
当使用默认的json-file方式时,所有的日志文件都输出到/var/lib/docker/containers/<contaner_id>/<container_id>-json.log
以Fluentd为例
1 | docker run --log-driver=fluentd ubuntu echo "Hello Fluentd!" |
对于垮主机的情况可以使用
1 | docker run --log-driver=fluentd --log-opt fluentd-address=192.168.50.101:24225 ubuntu echo "..." |
同时通过log-opt我们可以定义fluentd收集时的日志标签等信息
1 | docker run --log-driver=fluentd --log-opt fluentd-tag=docker.{{.ID}} ubuntu echo "..." |
而如上面的表所示,只有在logging driver为json-file或者journald时会才能支持使用docker logs查看日志信息,因此对于个别情况需要对单独容器进行容器查看的时候多少会带来很多麻烦,包括日志不实时\,查询复杂等。
1 | $ docker logs |
- 基于主机Agent的日志采集方式
上文有说docker默认使用json-file作为日志输出,同时所有的日志都会以Json的形式存储于日志文件当中/var/lib/docker/containers/<contaner_id>/<container_id>-json.log
通过对日志文件的收集,在满足中心化收集和处理容器日志的同时,还能支持对于单个容器的本地化操作。

日志输出规范
除了日志收集以外,我们还需要对于用户操作产生的日志做相关性处理,由于在微服务模式下应用程序可能由不同的服务是由不同应用开发框架完成,因此对于日志规范更多是“约定大于实现”。通过在各个服务中添加当前用户信息即可如user-
基于Fluentd搭建日志聚合分析平台
- Fluentd是什么?
Fluentd是一个开源的数据收集方案,用于统一数据的收集和处理。Fluentd通过类似于Data Pipeline的形式完成对日志以及其它格式化数据的统一收集和处理。
同时提供了大量的插件用以支持各种不同的需求如,日志持久化,告警通知等等。
- 在Rancher下部署Fluentd
这里主要分享基于Fluentd在Rancher下搭建日志聚合分析相关工具的内容。
用于示例的镜像可点击查看详情
创建fluentd配置文件内容如下所示:
1 | <source> |
这里我们添加了两个数据源分别是:
- forward以及tail,forward用于接收docker logging driver产生的日志;
- tail则实现对当前主机上的容器日志的统一收集。
为了将Fluentd的部署到Rancher的所有主机上,通过在服务启动时添加标签io.rancher.scheduler.global=true即可,当容器启动后Rancher会自动将Fluentd容器部署到所有Envionment下的Host主机
同时对主机的目录进行映射即可/var/lib/docker/containers:/var/lib/docker/containers
这里已经在Docker HUb构建了用于示例的镜像可点击查看详情
用于部署Rancher的docker-compose内容如下:
1 | version: '2' |
完整Catalog示例可访问:Github获取
Rancher Catalog中社区已经提供了ElasticSearch以及Kinana的相关Catalog,这里就不在过多说明了。
小结
日志聚合分析是支撑微服务架构应用的重要基础设施之一。同时通过对日志内容进行规范进行约定就可以达到对日志以及问题快速定位的需求,避免从技术层面引入更多的框架所引入的开发的复杂度。